在当今科技飞速发展的时代,多语言大模型数据研发已成为众多领域关注的焦点,这一领域的突破不仅能为人们的生活带来诸多便利,也为行业的发展注入了强大的动力。
多语言大模型数据研发有着极其重要的意义,它能够打破语言的障碍,让不同语言背景的人们能够更加顺畅地交流和获取信息,在全球一体化的趋势下,这种研发工作有助于促进文化的交流与融合,推动经济的合作与发展。
(图片来源网络,侵删)
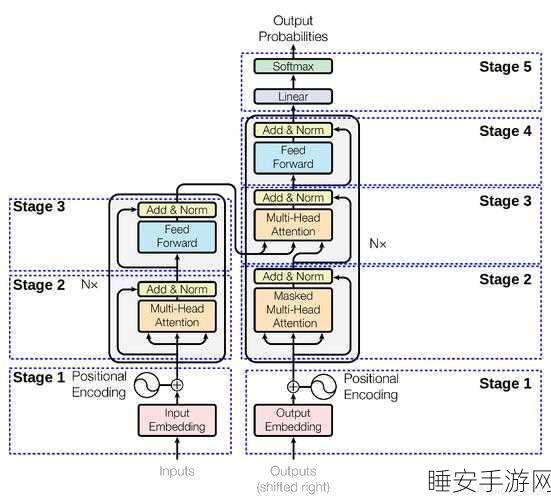
多语言大模型数据研发面临着诸多挑战,数据的收集和整理就是一个难题,不同语言的语法、词汇和表达方式差异巨大,要收集到全面、准确且具有代表性的数据并非易事,数据的质量和可靠性也至关重要,错误或不准确的数据可能会导致模型的偏差和错误,影响其性能和应用效果。
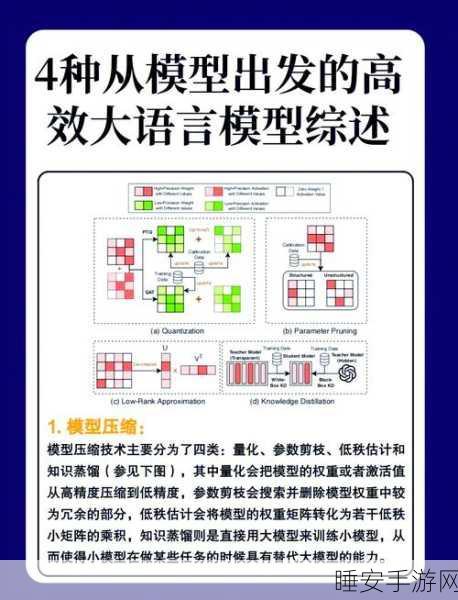
要实现多语言大模型数据研发的成功,需要采取一系列有效的策略,专业的团队是关键,团队成员应具备语言学、计算机科学、统计学等多领域的知识和技能,能够协同工作,共同攻克难题,先进的技术和工具也不可或缺,利用自然语言处理技术、机器学习算法等,能够提高数据处理和模型训练的效率和质量。
(图片来源网络,侵删)
持续的优化和改进也是必不可少的,多语言大模型数据研发是一个不断发展和完善的过程,随着新的语言现象和需求的出现,需要及时对模型进行调整和更新,以保持其准确性和实用性。
多语言大模型数据研发是一项充满挑战但前景广阔的工作,通过各方的努力和创新,相信在未来,我们将能够看到更加成熟和高效的多语言大模型,为人类社会的发展做出更大的贡献。
参考来源:相关行业研究报告及专家观点。